La importancia de optimizar hiperparámetros en modelos de Machine Learning aplicados a minería
En los últimos años, el uso de Machine Learning (ML) en minería ha crecido de manera significativa, particularmente en aplicaciones relacionadas con predicción de leyes, recuperación metalúrgica, clasificación geológica y variables geometalúrgicas como dureza, consumo energético o throughput.
Sin embargo, uno de los aspectos más importantes —y al mismo tiempo más subestimados— en el desarrollo de modelos predictivos corresponde a la optimización de hiperparámetros.
Es relativamente común encontrar estudios donde se comparan algoritmos utilizando únicamente parámetros por defecto. En muchos casos esto lleva a conclusiones incorrectas respecto al verdadero desempeño de los modelos. Un algoritmo, en apariencia, “malo” puede superar ampliamente a otro si sus hiperparámetros son ajustados de forma correcta.
En minería, donde los datasets suelen ser limitados, costosos y espacialmente correlacionados, la correcta optimización de hiperparámetros puede representar la diferencia entre un modelo robusto y uno por completo inutilizable operacionalmente.
El objetivo de este artículo es revisar:
- ¿Qué son los hiperparámetros?
- ¿Por qué son importantes?
- ¿Cómo afectan el desempeño de modelos ML?
- ¿Qué metodologías de optimización existen?
- Ejemplos aplicados a variables geometalúrgicas
- Riesgos asociados al sobreajuste
- Recomendaciones prácticas para minería
¿Qué son los hiperparámetros?
En términos simples, los hiperparámetros corresponden a configuraciones externas que controlan el comportamiento de un algoritmo de Machine Learning.
A diferencia de los parámetros internos del modelo, que son aprendidos automáticamente durante el entrenamiento, los hiperparámetros deben ser definidos por el usuario antes de entrenar el modelo.
Por ejemplo:
Random Forest
Algunos hiperparámetros típicos son:
- Número de árboles
- Profundidad máxima
- Número mínimo de muestras
- Cantidad de variables evaluadas por nodo
XGBoost
Entre los más relevantes se encuentran:
- Learning rate
- Número de estimadores
- Profundidad
- Regularización
- Subsampling
- Column sampling
Redes neuronales
En redes neuronales los hiperparámetros incluyen:
- Número de capas
- Cantidad de neuronas
- Learning rate
- Batch size
- Funciones de activación
- Dropout
- Optimizer
Todos estos parámetros afectan directamente la capacidad predictiva, la estabilidad, el tiempo de entrenamiento, la generalización y el riesgo de sobreajuste.
¿Por qué los hiperparámetros son tan importantes?
Dos modelos utilizando exactamente el mismo algoritmo pueden tener desempeños completamente distintos dependiendo de cómo se configuren sus hiperparámetros.
Por ejemplo:
- un modelo demasiado complejo puede memorizar ruido
- un modelo demasiado simple puede no capturar patrones reales
- un learning rate incorrecto puede impedir convergencia
- demasiados árboles pueden aumentar sobreajuste
- muy pocos árboles pueden generar underfitting
En minería, esto es especialmente relevante debido a:
- datasets relativamente pequeños
- alta variabilidad espacial
- ruido geológico
- presencia de outliers
- dominios complejos
- distribuciones altamente asimétricas
Un mal tuning puede llevar a modelos estadísticamente atractivos en entrenamiento, pero por completo inconsistentes al aplicarse sobre nuevas zonas del depósito.
Overfitting y underfitting
Uno de los principales objetivos de la optimización corresponde a encontrar el equilibrio correcto entre capacidad predictiva y generalización.
Underfitting: ocurre cuando el modelo es demasiado simple para capturar la complejidad real de los datos.
Consecuencias:
- bajo desempeño
- alto sesgo
- incapacidad de modelar relaciones no lineales
Ejemplos:
- árboles demasiado pequeños
- muy pocos estimadores
- regularización excesiva
Overfitting: ocurre cuando el modelo aprende ruido y particularidades específicas del conjunto de entrenamiento. En minería, esto es particularmente peligroso debido a la autocorrelación espacial.
Consecuencias:
- métricas artificialmente altas
- pobre desempeño en validación
- baja capacidad de extrapolación
Muchas veces un modelo parece extremadamente preciso simplemente porque las muestras de entrenamiento y validación se encuentran espacialmente cercanas.
Ejemplo de optimización de hiperparámetros
En este ejemplo se desarrolló un modelo de Random Forest Regressor con el objetivo de predecir la ley de una variable de interés a partir de un conjunto de variables geoquímicas.
Con el fin de maximizar la capacidad predictiva del modelo se utilizó Optuna, una biblioteca de optimización de hiperparámetros basada en técnicas de búsqueda inteligente que permiten explorar de manera eficiente el espacio de soluciones. A diferencia de enfoques tradicionales como Grid Search o Random Search. Optuna emplea algoritmos de optimización secuencial que aprenden de las evaluaciones previas para concentrar la búsqueda en las regiones más prometedoras. Durante el proceso, cada combinación de hiperparámetros fue evaluada mediante validación cruzada utilizando el coeficiente de determinación (R²) como métrica objetivo.
La Figura 1 presenta las curvas de validación obtenidas para los principales hiperparámetros del modelo optimizado. Estas curvas permiten visualizar cómo varía el desempeño del Random Forest a medida que cambia la complejidad del modelo. En general, se observa que valores muy bajos de complejidad conducen a situaciones de underfitting, donde el modelo es incapaz de capturar adecuadamente la variabilidad de la ley, mientras que configuraciones excesivamente complejas tienden a incrementar el riesgo de overfitting, reduciendo la capacidad de generalización sobre datos no observados. Los valores seleccionados por Optuna corresponden a la región donde el rendimiento en validación alcanza su máximo o se mantiene estable.
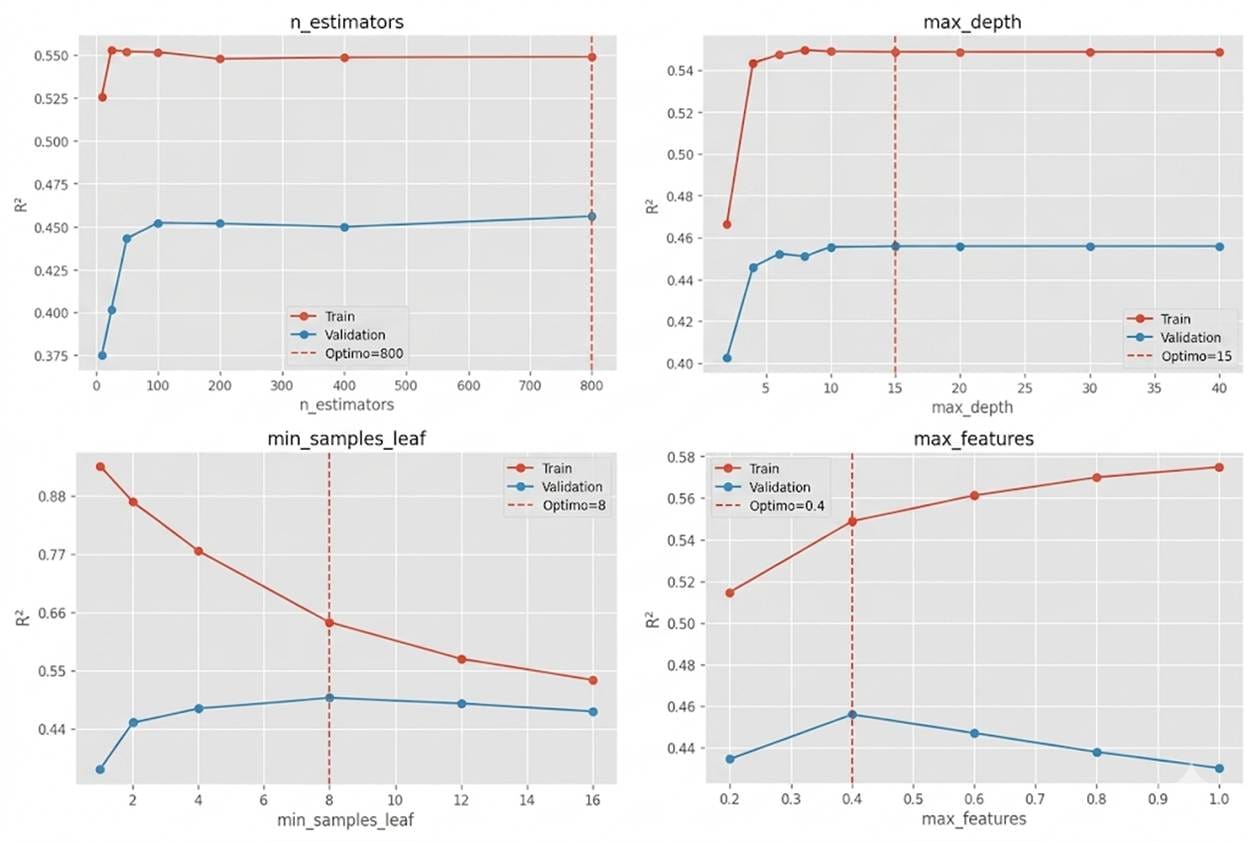
Los resultados obtenidos muestran claramente el beneficio de la optimización de hiperparámetros. El modelo base de Random Forest alcanzó un R² de 0.454, mientras que el modelo optimizado incrementó este valor hasta 0.696, lo que representa una mejora relativa del 53.25% en la capacidad explicativa del modelo. Asimismo, el RMSE disminuyó un 25.35% y el MAE se redujo un 16.54%, evidenciando una mejora significativa en la precisión de las predicciones. Estos resultados demuestran que la optimización sistemática de hiperparámetros constituye una etapa fundamental en el desarrollo de modelos predictivos para estimación de leyes permitiendo extraer un rendimiento considerablemente superior incluso a partir de algoritmos ya consolidados como Random Forest.
Reflexión final
La optimización de hiperparámetros representa uno de los aspectos más importantes en Machine Learning aplicado a minería. En muchos casos, las diferencias entre un modelo útil y uno inutilizable no dependen del algoritmo seleccionado, sino de cómo fue ajustado. Sin embargo, la optimización no debe entenderse únicamente como un problema matemático. En minería, los modelos deben respetar:
- coherencia geológica
- continuidad espacial
- dominios
- soporte
- comportamiento operativo
El verdadero desafío no consiste en construir el modelo con el mayor R², sino desarrollar modelos robustos, interpretables y capaces de generalizar correctamente en nuevas zonas del yacimiento. La combinación entre conocimiento geológico, geoestadística y optimización inteligente de Machine Learning representa actualmente una de las áreas más prometedoras para el desarrollo de modelos avanzados. Frente a esto, surge una pregunta cada vez más relevante: ¿cuántos modelos considerados “malos” en minería realmente fallaron por el algoritmo… y cuántos simplemente por un mal proceso de optimización?
