Integración de distintos soportes de datos en la estimación de corto plazo
El problema: datos de calidad y soporte distintos
En proyectos mineros es frecuente contar simultáneamente con dos o más fuentes de información geoquímica que difieren tanto en densidad de muestreo como en soporte físico: los sondajes de exploración (DDH o RC), tomados a lo largo de toda la vida del proyecto con espaciamientos significativos, y los blast holes (BH), muestreados de forma masiva durante la etapa de producción con mallas muy densas conforme avanza el minado. Ambas fuentes contienen información valiosa, pero integrarlas sin el debido cuidado puede introducir sesgos significativos en el modelo de recursos.
La pregunta central es: ¿cómo aprovechar la alta densidad espacial de los blast holes para mejorar la estimación de leyes a partir de los sondajes, sin comprometer la insesgadez del estimador? La respuesta está en el cokriging, pero para aplicarlo correctamente es necesario comprender primero algunos conceptos estadísticos y geoestadísticos fundamentales.
Relación volumen-varianza: sesgo y calidad
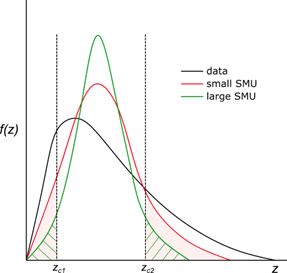
El soporte físico de una muestra —su volumen— afecta directamente su variabilidad estadística. Un blast hole representa un volumen de roca del orden de decenas de toneladas, mientras que un DDH compuesto en intervalos de 2 m representa apenas unos pocos kilogramos. Por la relación volumen-varianza, las muestras de mayor soporte presentan menor varianza y distribuciones más simétricas que las de soporte reducido (Donovan, 2015; Minnitt & Deutsch, 2014).
Esto implica que comparar directamente las distribuciones estadísticas de DDH y BH puede conducir a conclusiones erróneas sobre el sesgo entre ambas fuentes. Las muestras secundarias de tipo exhaustivo —como los blast holes— están sujetas a sus propias fuentes de sesgo, imprecisión y error. Donovan (2015) identifica tres etapas principales en las que estos problemas pueden originarse: el proceso de recolección, el análisis de laboratorio y la preparación de los datos por parte del analista.
Comparando distribuciones de fuentes totalmente heterotópicas
Antes de formular cualquier modelo de cokriging, es indispensable evaluar la comparabilidad estadística entre las dos fuentes de datos. Para ello se dispone de herramientas gráficas multivariadas y pruebas formales que, usadas en conjunto, permiten detectar sesgos sistemáticos y diferencias distribucionales entre ambas fuentes.
La pregunta central es si dos muestras provienen de la misma distribución o, de manera equivalente, si existe una diferencia sistemática en la magnitud medida. De forma análoga, puede preguntarse si una muestra es consistente con haber sido extraída de una distribución conocida. Las distribuciones pueden caracterizarse por su forma, ubicación y escala.
Entre las herramientas disponibles, los scatter plots permiten visualizar la correlación lineal y detectar outliers o grupos sistemáticos, mientras que los QQ-plots superpuestos revelan diferencias cuantil a cuantil entre ambas distribuciones.
Para complementar el análisis gráfico se utilizan pruebas de hipótesis. El test de Kolmogorov-Smirnov (KS) evalúa si dos muestras provienen de la misma distribución comparando la diferencia máxima entre sus funciones de distribución acumulada; es no-paramétrico y robusto ante la no-normalidad, aunque pierde potencia en las colas. El test de Anderson-Darling es más sensible a diferencias en las colas, lo que lo hace preferible cuando, por ejemplo, las leyes altas tienen mayor impacto económico.
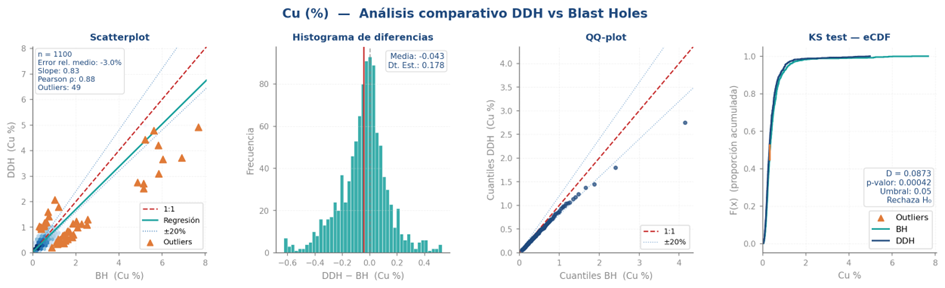
En la práctica, ninguna prueba por sí sola es concluyente. La recomendación es combinar las tres pruebas con las visualizaciones para caracterizar el comportamiento conjunto de ambas fuentes de datos. Cabe preguntarse, sin embargo, cómo realizar este análisis cuando no existen muestras en las mismas ubicaciones. La solución habitual es construir pares "gemelos" mediante un buffer de distancia, seleccionando pares de muestras entre ambos soportes dentro de una ventana de proximidad definida. La Figura 2 ilustra este análisis integrado para una base de datos hipotética de Cu.
Adicionalmente, el coeficiente de correlación entre pares migrados es un criterio práctico indispensable para definir la estrategia de integración. Siguiendo los criterios de Minnitt y Deutsch (2014) y Donovan (2015), cuando la correlación supera 0,8 ambas fuentes pueden combinarse directamente; entre 0,7 y 0,8 la SCOK generalmente mejora las estimaciones; por debajo de 0,7 su eficiencia se vuelve cuestionable y los resultados deben interpretarse con cautela.
Homotopía y heterotopía
En geoestadística multivariada se dice que dos variables son homotópicas cuando cada muestra de una variable tiene una muestra colocada (misma ubicación) de la otra. En la práctica, esto rara vez ocurre para informaciones de distintos soportes: los DDH y los BH muestrean distintos lugares del depósito. Esta condición se denomina heterotopía y tiene consecuencias directas sobre cómo se calculará el modelado espacial y las estimaciones de ambas variables. Cuando los datos son totalmente heterotópicos, el variograma cruzado experimental entre sondajes y pozos no puede calcularse, no existen pares colocados; el variograma cruzado experimental solo puede calcularse a datos homotópicos. La ecuación abajo del variograma cruzado define que se obtenga la información de la variable “Z” primaria y secundaria “Y” en la misma ubicación “u”:
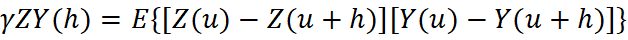
Para lidar con ello existen algunas alternativas:
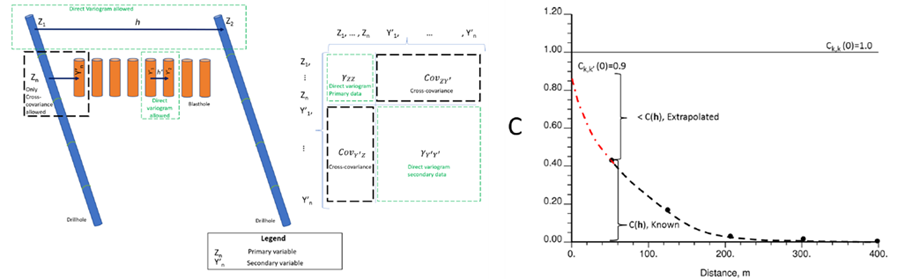
- Extrapolacción de la covarianza y inferencia del variograma cruzado: según Davila & Deutsch, 2022 la covarianza cruzada puede calcularse y extrapolarse hasta el origen en la distancia:
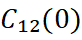
y el variograma cruzado puede inferirse (Cuba & Deutsch, 2012). Este detalle tiene importancia práctica: una correlación cruzada mal extrapolada sobreestima o subestima la contribución de la variable secundaria al estimador.
- Modelado Lineal de Corregionalización (MLC) directo de las covarianzas cruzadas para n distancias.
- Modelado Intríseco de Corregionalización (MCI) es un caso particular del MLC donde el coeciente de correlación regionalizado es lo mismo para ambas escalas (la correlación es independente de la escala espacial). En este caso, los variogramas directos y cruzados son propocionales a un mismo variograma:
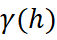
con una o más estructuras:
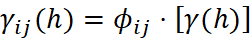
El Modelo Lineal de Corregionalización (MLC)
Para cualquier variante de cokriging, los variogramas directos y el variograma cruzado entre ambos deben modelarse conjuntamente de forma consistente. Esta exigencia se formaliza en el Modelo Lineal de Corregionalización (MLC), que descompone cada variograma en N estructuras anidadas. La condición indispensable es que la matriz de coeficientes:
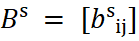
sea semidefinida positiva para cada estructura N. En el caso bivariado, esto se reduce a exigir que:
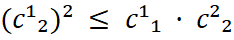
por estructura. Si esta condición se viola, el sistema de cokriging puede producir varianzas negativas.
En la práctica, el ajuste simultáneo del MLC con tres variogramas (directos y cruzado) es la parte más laboriosa del flujo de trabajo. Herramientas como Isatis.neo, RMSP y otros softwares de geoestadística permiten ajustar el MLC de forma interactiva con validación automática de la condición de semidefinición positiva. Una alternativa para múltiples variables correlacionadas es la decorrelación mediante factores PCA/MAF (Min/Max Autocorrelation Factors)/PPMT, que permite modelar y simular cada factor de forma independiente.
El Modelo de Corregionalización Intríseco (MCI)
El Modelo de Corregionalización Intrínseco (MCI) es un caso particular del Modelo Lineal de Corregionalización (MLC), en el que todos los variogramas directos y cruzados de las variables analizadas son proporcionales a un mismo variograma base. Este variograma puede estar compuesto por una o más estructuras fundamentales, obedeciendo la siguiente propiedad matemática:
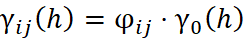
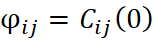
donde:
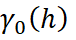
representa un modelo de variograma con meseta unitaria;
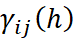
es el variograma directo o cruzado entre las variables i y j;
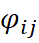
es el coeficiente de proporcionalidad entre los variogramas de las distintas variables;
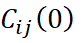
es el valor de la matriz de covarianza en el lag cero.
En este contexto, el MCI simplifica la modelización de la dependencia espacial entre múltiples variables al asumir que todas comparten la misma estructura espacial básica, diferenciándose únicamente por los coeficientes de proporcionalidad. Este enfoque reduce la complejidad computacional de la modelización geoestadística multivariada, garantizando coherencia estadística entre los variogramas directos y cruzados.
Métodos de estimación multivariable: cokriging
El cokriging es una generalización del kriging para múltiples variables que proporciona un estimador insesgado de varianza mínima. Este método incorpora la correlación espacial entre variables mediante la función de covarianza cruzada, permitiendo utilizar información secundaria sin necesidad de muestreo exhaustivo. Los datos pueden estar ubicados en los mismos puntos de la variable primaria o distribuidos en posiciones espaciales distintas, lo que hace del cokriging una aproximación flexible para modelamiento geoestadístico multivariado.
El objetivo es mejorar la estimación de la variable primaria al incorporar información de variables secundarias más densamente muestreadas, especialmente, cuando la variable primaria presenta baja autocorrelación espacial mientras que las variables secundarias tienen mayor continuidad espacial.
Un beneficio principal del cokriging es la reducción de la varianza del error de estimación, ya que aprovecha la correlación entre variables para mejorar la precisión. Por tanto, la varianza del error del cokriging siempre será menor o igual a la del kriging simple, haciéndolo más eficiente para modelamiento geoestatístico multivariado.
El estimador del cokriring simple puede ser definido como:
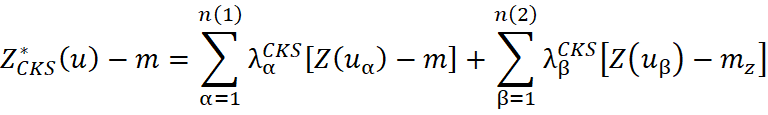
donde:
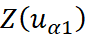
y
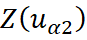
son valores de variables aleatorias primaria y secundaria;
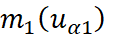
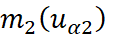
representan la media de las variables;
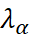
y
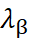
son los pesos del cokriging calculados a partir de las covarianzas entre las muestras primarias y secundarias.
Cokriging simple
El cokriging simple asume medias estacionarias y conocidas para ambas variables. Es el más eficiente en varianza, pero sensible a errores en las medias globales. En la práctica minera se usa poco porque rara vez se conocen con certeza las medias de todo el depósito, especialmente en etapas tempranas del proyecto.
Cokriging ordinario
En el cokriging ordinario la media se considera estacionaria únicamente dentro de una vecindad local, en contraste con la cokriging simple, que asume estacionariedad en toda el área de estudio. El estimador del cokriging ordinario para la variable de interés en el punto se expresa como:
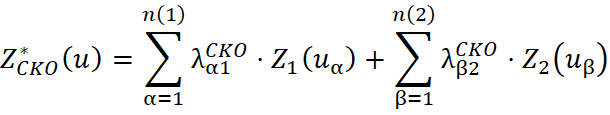
Bajo las condiciones convencionales del cokriging ordinario, la suma de los pesos de la variable primaria es igual a 1, mientras que la suma de los pesos de la variable secundaria es igual a 0:
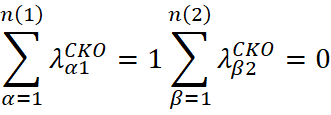
Sin embargo, en la práctica, esta restricción sobre los pesos de la variable secundaria puede generar pesos negativos o muy pequeños, lo que puede producir estimaciones negativas o reducir excesivamente la influencia de la variable secundaria en el modelo.
Cokriging ordinario estandarizado (SCOK)
El Cokriging Ordinario Estandarizado (SCOK) descrito por Goovaerts (1997) es una metodología diseñada para incorporar datos de calidad variable, considerando tanto las autocorrelaciones como las correlaciones cruzadas espaciales entre las variables involucradas. Este método también reduce el sesgo introducido por conjuntos de datos imprecisos, al operar con residuos estandarizados en lugar de los datos originales, lo que garantiza estimaciones más robustas y coherentes.
La SCOK surge como una alternativa a la restricción sobre los pesos de la variable secundaria en la COK, reemplazando las dos condiciones anteriores por una única restricción: la suma total de todos los pesos debe ser igual a 1:
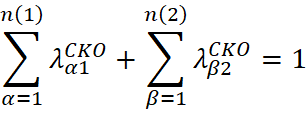
La SCOK ha sido recomendada en la industria minera para estimaciones de corto y mediano plazo cuando se integran datos de distinta calidad (Davila & Deutsch, 2022). En casos completamente heterotópicos, es habitual modelar directamente las covarianzas cruzadas mediante el MLC, o simplificar la estructura de los variogramas a través del MCI.
Cokriging colocado
En algunos casos, no muy frecuentes en minería, la variable secundaria está significativamente más muestreada que la primaria y la información secundaria ya se encuentra disponible en el punto donde se desea estimar la variable de interés. El cokriging colocado es una aproximación que aprovecha esta información para mejorar la estimación de la variable primaria. En bases de datos donde la cantidad de muestras primarias es igual o superior a la de muestras secundarias, la influencia de muestras primarias lejanas puede comprometer la calidad de la estimación. Este problema puede resolverse mediante Modelos de Markov, que proponen utilizar exclusivamente la información secundaria colocalizada. La cokrigaje colocada es más común cuando la información secundaria es exhaustiva, y se aplica ampliamente en casos donde se integran datos geofísicos o de teledetección en la estimación.
Validación cruzada: kfolds
Una vez obtenidas las estimaciones, es necesario evaluar su calidad de forma objetiva antes de adoptar cualquier metodología como definitiva. Para ello se recurre a la validación cruzada, que consiste en estimar ubicaciones conocidas a partir del resto de los datos y comparar el valor estimado con el valor real. En el contexto de integración de sondajes DDH con blast holes, Donovan (2015) recomienda aplicar esta validación de forma cuidadosa, dado que el uso de datos secundarios con sesgo en el conjunto de entrenamiento puede comprometer la interpretación de los resultados si el conjunto de validación no está correctamente aislado. Por esta razón, el conjunto de validación debe estar compuesto exclusivamente por muestras DDH, que representan la fuente de mayor confianza y calidad, mientras que el conjunto de entrenamiento combina DDH y blast holes según el método evaluado.
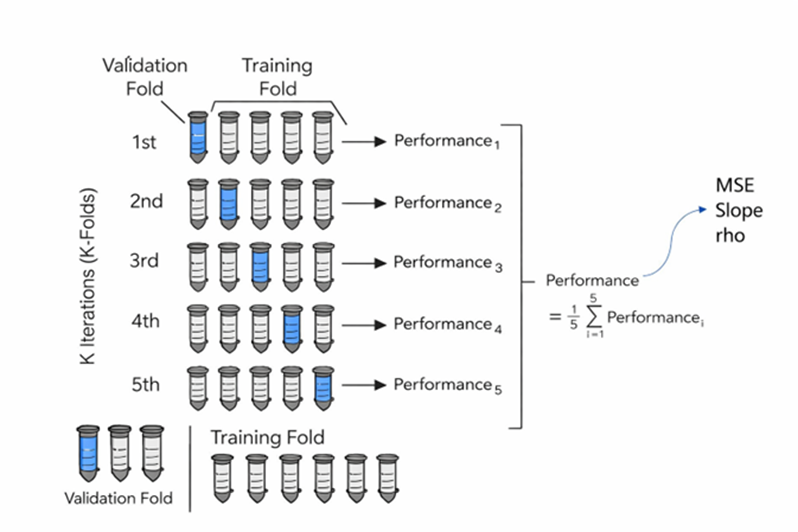
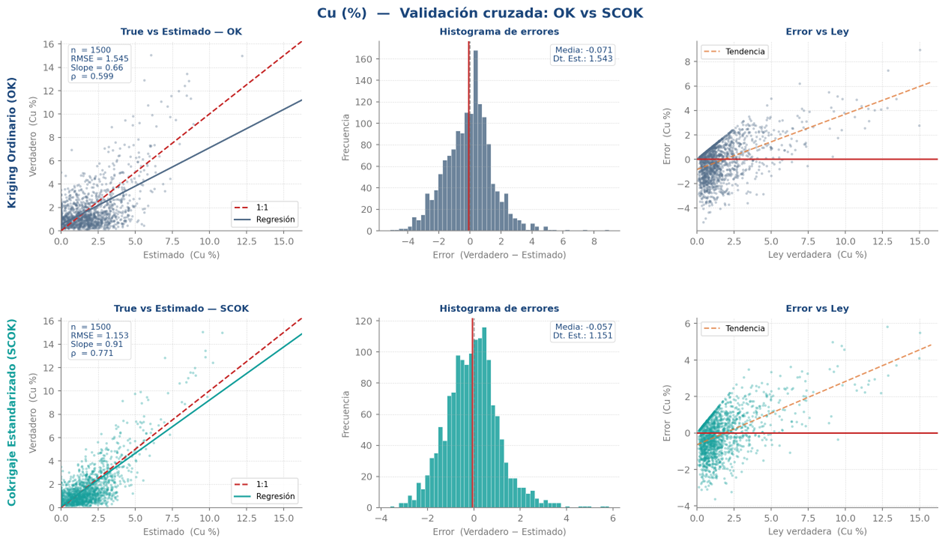
Para robustecer la comparación entre métodos, se recomienda aplicar una validación cruzada tipo K-Folds con K = 5 iteraciones. En cada iteración, el 20% de los sondajes DDH es removido aleatoriamente y utilizado como conjunto de validación, mientras que el 80% restante se combina con las muestras de blast holes para estimar los valores en las ubicaciones removidas. Este procedimiento se repite cinco veces de modo que la totalidad de los sondajes DDH es utilizada exactamente una vez como validación, garantizando que cada partición sea independiente y representativa espacialmente. El desempeño final de cada método corresponde al promedio de las métricas calculadas en cada fold, considerando el coeficiente de correlación de Pearson, el error cuadrático medio (MSE) y la pendiente de la recta de regresión entre valores estimados y reales. La comparación sistemática de estos indicadores entre métodos permite identificar cuál técnica reproduce mejor la variable primaria y con menor sesgo condicional, orientando así la selección de parámetros y la decisión metodológica final. La Figura 4 ilustra un ejemplo de validación cruzada en una comparación para Cu (%) entre krigaje ordinaria (OK) y cokrigaje ordinario estandarizado (SCOK).
Flujo de trabajo práctico y recomendaciones
La integración de blast holes y sondajes en un modelo geoestadístico robusto requiere seguir un flujo de trabajo ordenado, en el que cada etapa condiciona las decisiones de la siguiente. A continuación, se describen los pasos críticos del proceso recomendado.
Análisis comparativo de las distribuciones: el punto de partida es la comparación estadística entre las distribuciones de DDH y BH mediante pares de muestras construidos en distintas distancias con un buffer de proximidad. Se utilizan scatter plots, QQ-plots y tests formales como Kolmogorov-Smirnov y Anderson-Darling para cuantificar diferencias en forma, ubicación y escala. Es fundamental identificar si existe sesgo sistemático entre las fuentes y evaluar el coeficiente de correlación entre pares migrados, ya que este determina directamente la viabilidad y eficiencia de cualquier estimación multivariada posterior.
Definición de las técnicas a comparar: a partir del análisis distribucional y de correlación es posible establecer qué estrategias son aplicables. Cuando la variable secundaria presenta mayor densidad espacial que la primaria y la correlación entre ambas es plausible, se recomienda el uso de la SCOK como metodología principal. Sin embargo, es recomendable incluir en la comparación estimaciones alternativas, como kriging ordinarip con datos separados o con datos combinados sin corrección, para disponer de una línea base que permita cuantificar el beneficio real de la integración.
Modelado espacial: esta etapa comprende la construcción del modelo de continuidad espacial adecuado para cada técnica evaluada. Para la SCOK, se requiere el ajuste del Modelo Lineal de Corregionalización (MLC) mediante covarianzas cruzadas, o su simplificación mediante el Modelo de Corregionalización Intrínseca (MCI) cuando la estructura espacial de ambas variables es proporcional. Para estimaciones con datos combinados se modela un variograma único. En todos los casos deben evaluarse las anisotropías geológicas y la orientación de los dominios estacionarios definidos.
Validación cruzada: la comparación entre métodos se realiza mediante validación cruzada K-Folds (K = 5) sobre los sondajes DDH, que constituyen la fuente de referencia. En cada iteración, el 20% de los DDH es reservado como conjunto de validación, mientras el 80% restante se combina con los blast holes para la estimación. Las muestras se seleccionan dentro de un buffer espacial que garantice la coexistencia de ambas fuentes, evitando sesgos espaciales en los resultados. Las métricas de desempeño, RMSE, sesgo medio y correlación de Pearson, se promedian entre las cinco iteraciones para obtener una evaluación robusta e independiente de la partición.
Estimación en bloques y análisis comparativo: una vez seleccionada la metodología, se procede a la estimación completa del modelo de bloques con ambas técnicas para fines de comparación. Validaciones visuales, swath plots, curvas teor-tonelaje y estadísticas globales permiten evaluar las diferencias en suavizado, reproducción de la variabilidad y comportamiento en las colas de la distribución. Las reconciliaciones con producción real, cuando están disponibles, constituyen la validación más definitiva.
Selección del método e integración final: la decisión final debe basarse en el conjunto de evidencias acumuladas a lo largo del flujo: coherencia estadística entre fuentes, desempeño en validación cruzada, comportamiento visual del modelo y consistencia con el conocimiento geológico del depósito. El objetivo no es seleccionar el método más sofisticado, sino el que mejor reproduce la realidad con los datos disponibles y dentro de las condiciones de estacionariedad del dominio analizado.
Literatura relacionada
La integración de datos de diferente calidad y soporte en estimación de recursos minerales ha sido ampliamente estudiada en la literatura geoestadística. Donovan (2015) establece que las diferencias estadísticas observadas entre sondajes y blast holes pueden ser un artefacto del soporte físico y no necesariamente un sesgo real de muestreo, dado que la relación volumen-varianza implica que muestras de mayor soporte presentan menor varianza y distribuciones más simétricas. Séguret (2015), en un estudio aplicado en un depósito de cobre porfírico en el norte de Chile, demuestra mediante deconvolución y variograma cruzado que ambas fuentes son coherentes en su estructura espacial y pueden interpretarse como regularizaciones de la misma realidad, aunque cada una porta su propio error de medición independiente.
Frente a este problema, el cokriging se consolida como la metodología más adecuada para integrar fuentes de distinta calidad sin transferir el sesgo ni la imprecisión a las estimaciones. Minnitt y Deutsch (2014) demuestran que el cokrigaje ordinario estandarizado (SCOK), apoyado en un Modelo Lineal de Corregionalización (MLC), mejora significativamente la estimación de reservas recuperables frente a la krigaje ordinaria, incluso cuando los datos secundarios presentan errores importantes y sesgo multiplicativo. Araújo y Costa (2015) confirman estos resultados en escenarios de planificación de corto plazo, mostrando que la SCOK reduce la misclasificación de bloques y produce curvas teor-tonelaje más cercanas a la distribución real, mientras que Bassani et al. complementan el análisis discutiendo las implicaciones prácticas de la heterotopía y la diferencia de soporte en la construcción de modelos de recursos integrados.
Referencias
Araújo, C.P. & Costa, J.F.C.L. (2015). Integration of different-quality data in short-term mining planning. REM: Revista Escola de Minas, 68(2), 221–227.
Bassani, M.A.A. et al. Integration of data from different supports in mineral resource estimation. [Tesis doctoral]. Universidade Federal do Rio Grande do Sul.
Cuba, M. & Deutsch, C.V. (2012). Inference of the cross variogram. Geostatistics Lessons. Recuperado de geostatisticslessons.com
Davila, F. & Deutsch, C.V. (2022). Standardized ordinary cokriging. Geostatistics Lessons. Recuperado de geostatisticslessons.com
Donovan, P. (2015). Resource Estimation with Multiple Data Types [Tesis de maestría]. University of Alberta.
Goovaerts, P. (1997). Geostatistics for natural resources evaluation. Oxford University Press.
Harding, A. & Deutsch, C.V. (2019). Volume variance relations. Geostatistics Lessons. Recuperado de geostatisticslessons.com
Minnitt, R.C.A. & Deutsch, C.V. (2014). Cokriging for optimal recoverable reserve estimates in mining operations. Journal of the Southern African Institute of Mining and Metallurgy, 114, 189–203.
Séguret, S.A. (2015). Geostatistical comparison between blast and drill holes in a porphyry copper deposit. En Proceedings of the 7th International Conference on Sampling and Blending, Bordeaux, Francia.

